AWS Glue offers fully managed, serverless and cloud-optimized extract, transform and load (ETL) services. Built for any job, it allows customers the flexibility of processing large quantities of data, while relying on AWS to manage the overall service and deal with the setup behind the scenes.
AWS Glue ETL Jobs provide fully managed access to several ways of processing your data. At its heart, it is based on Data Processing Units (DPU) that are used to run your job. DPUs are billed in per-second increments with a 10-minute minimum duration per job. There is a minimum of 2 DPUs per job run.
The beauty of this setup is how simple it is to scale up the processing power while not having to worry about coordination or managing a cluster yourself.
Let’s say you’ve been testing with a small dataset and now you’re ready to run your job on real data. While testing, you didn’t need a lot of DPUs, as you were working with a relatively small amount of data. Now that you want to run a large amount of data through your ETL Job, you want to ensure Glue completes processing the data just as fast as your smaller, test dataset.
Time to crank up the DPUs! If you were using 5 for your small data, 75 might do the trick on your larger dataset. Lets test it out.
Edit your job:
And then click on “Script libraries and job parameters”:
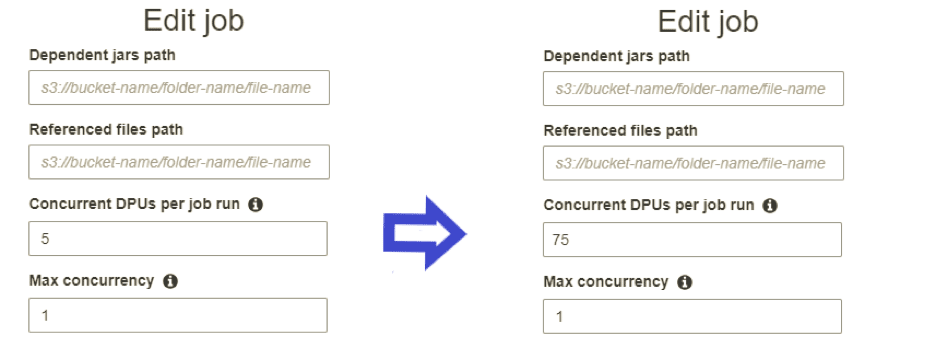
Done! You’ve just scaled your job’s DPUs by 1,500% !
Enter ETL Job profiling metrics:
To run AWS Glue ETL jobs efficiently, you need to dive into the recently released Job Profiling Metrics to get a detailed view of what is going on with your job. You can enable them by clicking on your job, going to Edit and then Advanced Properties.
After you run your job, if you look at the cpuSystemLoad metric, you can see that most of the processes on the DPUs finished early and only a few were busy the entire time.
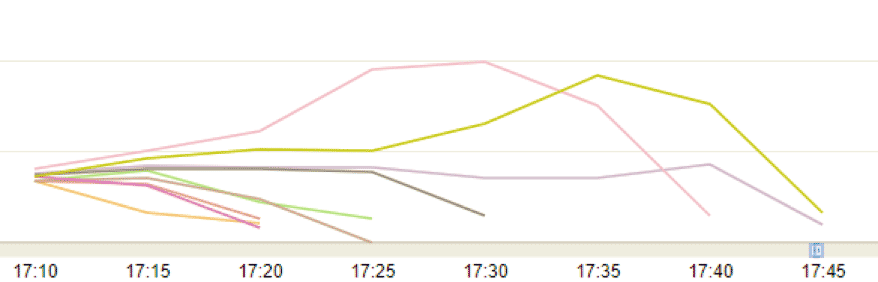
You will want to tweak how many DPUs you allocate so that all the processes finish as close together as possible. An easy way to start, is by finding a metric that helps maximize your DPU utilization, such as average file size, or total data size of the input dataset. For example, maybe you add 1 DPU for every 10GB of data you need to process.
Depending on the input format, you may also want to break up the datasets into multiple files. Gzipped files cannot be split for faster processing, while CSV files can.
You may find that after a certain point, more DPUs don’t speed up your ETL Jobs. With a little tweaking, you can find the optimal number of DPUs for your job, minimizing the cost per ETL job run.
BOTTOM LINE: BETTER PERFORMANCE FOR LOWER COST !
